Les dades es poden codificar en un format text que és accessible per qualsevol programa o usuari humà.
Entorn de treball
Per treballar amb documents XML farem servir {% link “/project/vscode/” %}.
Tens que instal.lar l’extensió XML Language Support de RedHat.
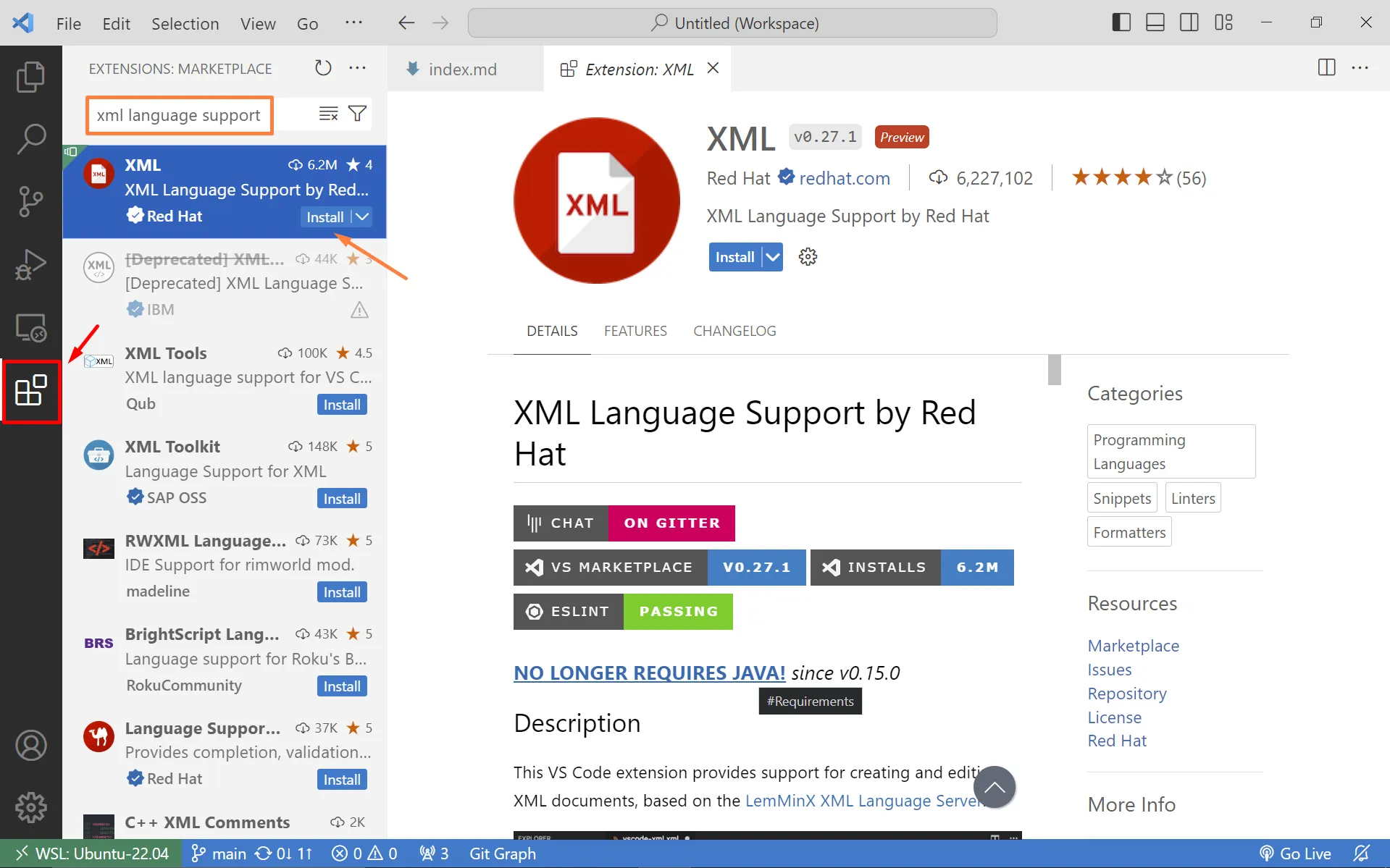
XML
XML és l’acrònim de EXtensible Markup Language.
XML és una llenguatge per representar dades estructurades en format text.
Format
Les dades es poden codificar en format binari o format text:
El format binari és més eficient, però només un programes específics el poden fer servir per codificar o decodificar dades.
El format text és menys eficient, però és accessible per qualsevol programa o usuari humà.
Format binari
Normalment el format binari el fan servir aplicacions concretes per guardar les dades, o per comunicarse amb clients específics.
Per exemple, la base de dades PostgresSQL pot decodificar aquest seqüència de bits perquè utilitza els seu protocol intern:
010001000010101010010010101001000000111000111Però cap altre aplicació, i molt menys un usuari humà pot decodificar la seqüència binaria per obtenir unes dades.
Encara que sigui molt eficient, les dades codificades no es poden compartir fàcilment.
Format text
Unes dades en format text es poden compartir molt fàcilment.
És un format tant portable que inclús tu, un usuari humà, pots llegir aquestes dades en un editor de text.
Tot en informàtica es codifica en bits, però quan codifiquem text aquests bits s’agrupen de manera estandarizada de manera que sempre formen números.
Cada número representa un caràcter.
Per exemple:
- Tenim la seqüència de bits
1100001 1100001en binari correspon al nombre97en decimal.- El nombre
97correspon al caràcterasi utilitzes UTF-8
Avui en dia, l’estàndar UTF-8 és el més utilitzat per codificar text per compartir.
Per exemple, gairebé tots els documents HTML estan codificats en UTF-8.
Per aquest motiu, tots els documents XML i HTML5 estan codificats en UTF-8 a no ser que indiquin un charset concret.
Entendible
Aquest és un exemple de dades textuals que qualsevol persona, humà o ordinador, pot entendre i compartir:
<book> <title>In Search of Lost Time</title> <author>Marcel Proust</author></book>Marcatge
XML és un llenguate per representar dades estructurades mitjançant marcatge (Markup).
Per exemple, si tinc les dades ("Toyota", "4"), intenta adivinar que volen dir.
Crea un fitxer data.xml.
Si les marco d’aquesta manera segur que pots entendre a que fan referència aquestes dades perquè estan marcades:
<person> <name>Toyota</name> <age>4</age></person>També les podriem marcar d’aquesta manera:
<car> <brand>Toyota</brand> <cylinders>4</cylinders></car>Les dades ("Toyota", "4") poden representar moltes coses si no estan marcades.
Dades tabulars
L’ús de XML per marcar dades augmenta la seva mida, de vegades molt.
Crea un fitxer clients.xml:
<clients> <client> <name>John</name> <surname>Smith</surname> <email>john@gmail.com</email> </client> <client> <name>Anne</name> <surname>Hathaway</surname> <email>anne@gmail.com</email> </client> <client> <name>Marie</name> <surname>Curie</surname> <email>marie@gmail.com</email> </client></clients>L’objectiu de XML es representar dades estructurades, no crear fitxers petits.
Per això, quan les dades són tabulars el format més habitual és representar les dades amb el format de text CSV tal com pots veure a continuació.
Crea el fitxer clients.csv:
John, Smith, john@gmail.comAnne, Hathaway, anne@gmail.comMarie, Curie, marie@gmail.comPots instal.lar l’extensió “Rainbow CSV”.
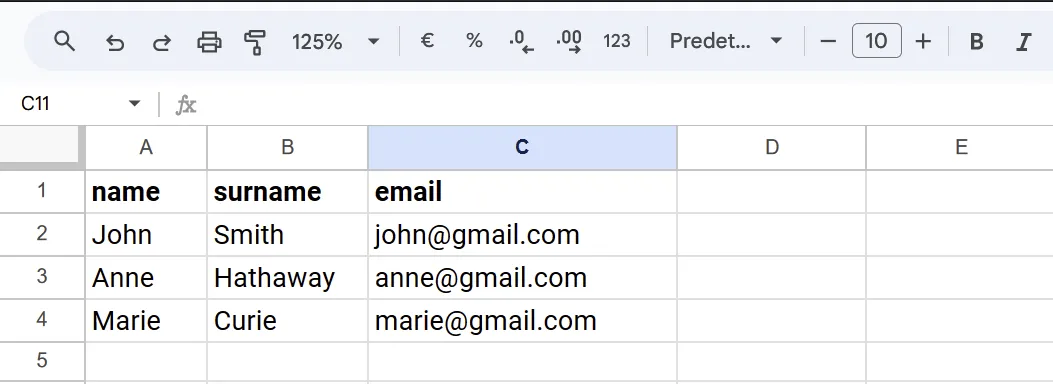
Les dades són tabulars quan es poden representar en un taula.
Per exemple, si tenim una llista de persones el més habitual és fer servir taula:
| name | surname | |
|---|---|---|
| John | Smith | john@gmail.com |
| Anne | Hathaway | anne@gmail.com |
| Marie | Curie | marie@gmail.com |
Aquesta taula pot estar en un fulla d’excel, que és el més habitual si saps ofimàtica:
També pot estar en una taula d’una base de dades {% link “/data/postgres/” %}
TODO. Canviar imatge
Relacions
Com ja saps de {% link “/data/postgres/” %}, les dades estan relacionades.
Hi ha molts conjunts de dades que no es poden representar amb una sóla taula.
Per exemple:
classDiagram
class Client {
+name
}
class Order {
+id
}
Order --> Client
class OrderItem {
+quantity
}
OrderItem --> Order
OrderItem --> Product
class Product {
+name
}
Aquestes dades es poden representar mitjançant dos models:
-
Model relacional. Conjunt de taules en que cada taula té un conjunt d’atributs que són la clau primaria de la fila, i que pot ser referenciada per files d’altres taules.
-
Model en xarxa. Cada dada està enllaçada amb altres dades formant una xarxa (així es com es representen les dades en el codi i les bases de dades en xarxa)
Subconjunt de dades
XML és un model jeràrquic (una restricció del model de xarxes) que ens permet representar un subconjunt de dades relacionades de manera jeràrquica.
Per exemple, un subconjunt de dades del model anterior podria ser aquest:
<order> <client> <name>Hellen</name> </client> <order-item> <product> <name>HP Elite Desktop Computer</name> </product> <quantity>1</quantity> </order-item> <order-item> <product> <name>Sculpt Confort Desktop</name> </product> <quantity>1</quantity> </order-item></order>Aquest format és molt útil per compartir dades entre sistemes, i fins l’arribada de {% link “/data/json/” %} era el format de dades més utilitzat.
Model jeràrquic
Com hem dit abans XML és un model jeràrquic: sempre hi ha un node principal del qual descendeixen els altres nodes.
La metàfora és la d’un arbre invertit en què una fulla neix d’una branca, i cada branca neix d’una altra branca, i aquesta d’una altra branca o de l’arrel de l’arbre.

El mòdel anterior es pot representar com un arbre invertit:
flowchart TD c(client) cn(name) cnv[[Helen]] c --> cn .-> cnv o(order) oi1(order-item) oi2(order-item) p(product) pn(name) pnv[[HP Elite Desktop Computer]] pq(quantity) pqv[[1]] o --> c o --> oi1 --> p p --> pn .-> pnv p --> pq .-> pqv o --> oi2
Pensant en un arbre pots entendre els noms que es fan servir en XML:
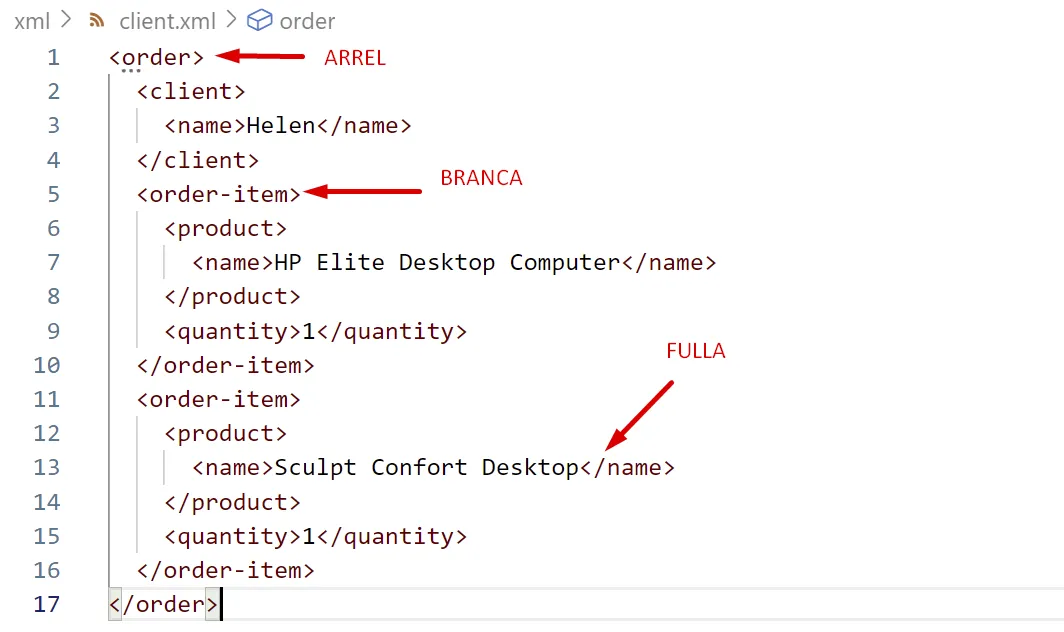
XML
Components
Etiqueta
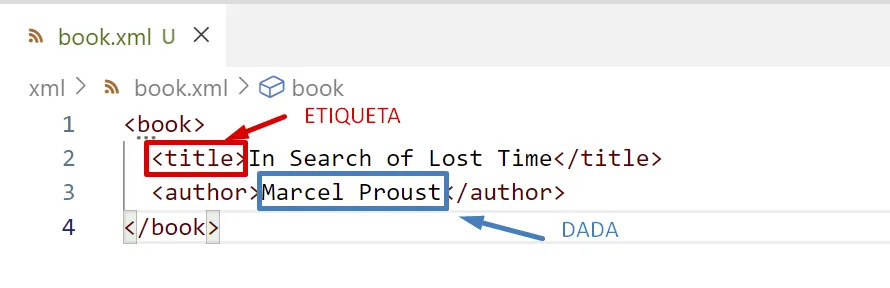
El text que comença per un caràcter < i acaba amb un caràcter > és una etiqueta XML.
El que no està envoltat de < i > són dades.
Aquesta regla fa molt fàcil distingir les dades del marcatge.
Element
Una etiqueta d’obertura sempre ha de tenir una etiqueta de tancament:
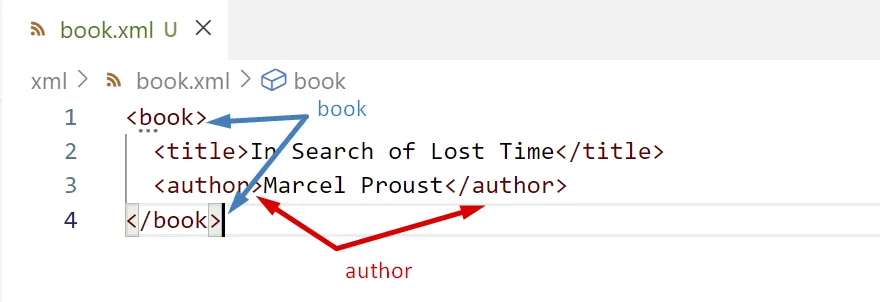
En llenguatge XML s’anomenen etiquetes d’inici i etiquetes finals.
Les etiquetes finals són les mateixes que les etiquetes inicials, excepte que tenen una / just després de l’obertura del caràcter <.
Tot el contingut des de l’etiqueta d’inici fins a l’etiqueta final, incloent aquestes etiquetes, s’anomena element.
Per exemple:
<title>és una etiqueta d’inici</title>és una etiqueta final<title>In Search of Lost Time</title>és un element
Contingut
El text entre l’etiqueta inicial i l’etiqueta final d’un element s’anomena contingut de l’element.
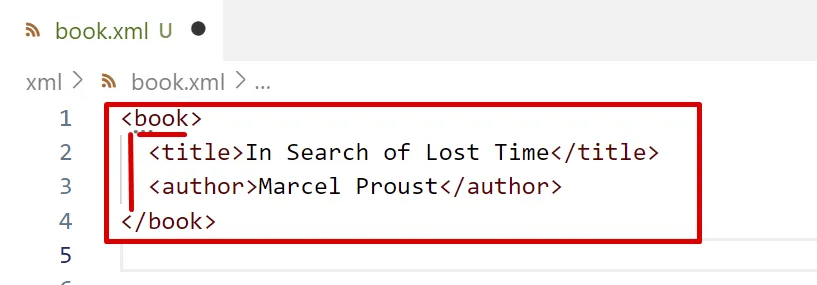
El contingut d’un element pot ser:
- Altres elements
- Text (
PCDATA)
L’element book comença a l’etiqueta <book> i acaba a l’etiqueta </book> i inclou tots els elements del document.
L’element book és l’element arrel del document.
Regles per als elements
Els documents XML han de complir determinades regles per estar ben formats. Cada etiqueta inicial ha de tenir una etiqueta final
Imagina’t que algú ha escrit això:
<book><title><author>Marcel ProustSegur que saps interpretar aquestes dades pel significat de cada etiqueta: és un llibre de Marcel Proust.
Però per un programa d’ordinador és un llibre que té un títol, i el títol (no pas el llibre) té un autor.
<book> <title> <author>Marcel ProustPer tant l’autor del títol és Marcel Proust!
flowchart LR book --> title --> autor autor .-> an an[[Marcel Proust]]
Recorda que en XML l’etiqueta final és necessària i el seu nom ha de coincidir exactament amb el nom de l’etiqueta inicial.
També que XML distingeix entre majúscules i minúscules!
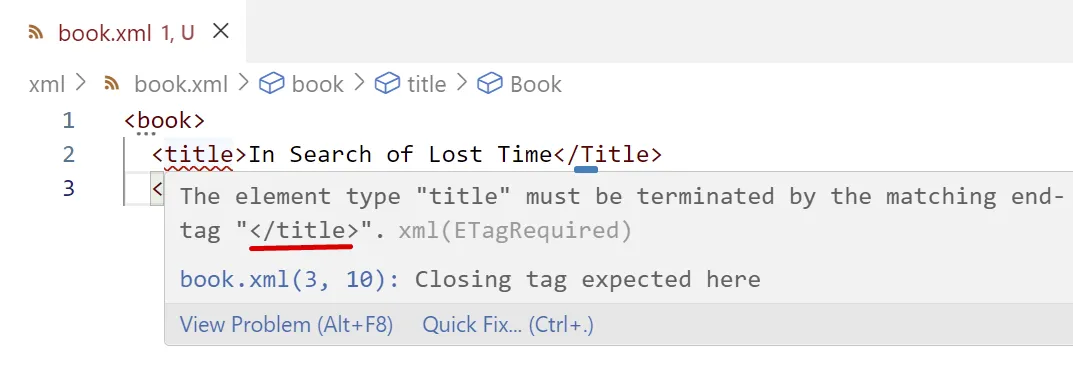
<title> i <Title> són dos etiquetes diferents.
Els elements s’han d’anidar correctament
Com que XML és estrictament jeràrquic has de tancar els elements fills abans de tancar els pares
Mira aquest exemple:
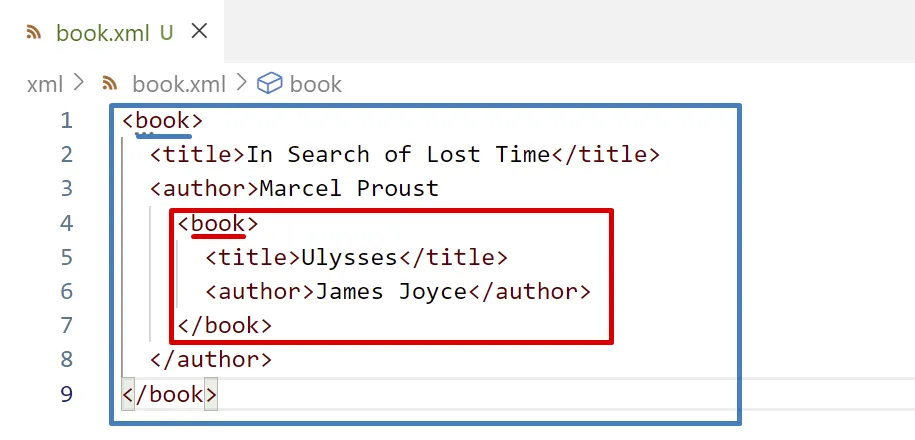
Segur que pots analitzar correctament aquesta estrutura XML perquè pots detectar els errors d’imbricació i saber quins elements són pares de quins altres elements i a quin element pertany cada fragment de text.
Però un analitzador XML no pot fer-ho!
Un document XML només pot tenir un element arrel
En el document XML anterior, l’element <book> s’anomena element arrel.
Aquest és l’element de nivell superior del document, i tots els altres elements són els seus fills o descendents.
Un document XML ha de tenir un i només un element arrel: de fet, ha de tenir un element arrel encara que no tingui contingut.
Per exemple, el següent XML no està ben format, perquè té dos elements arrel:
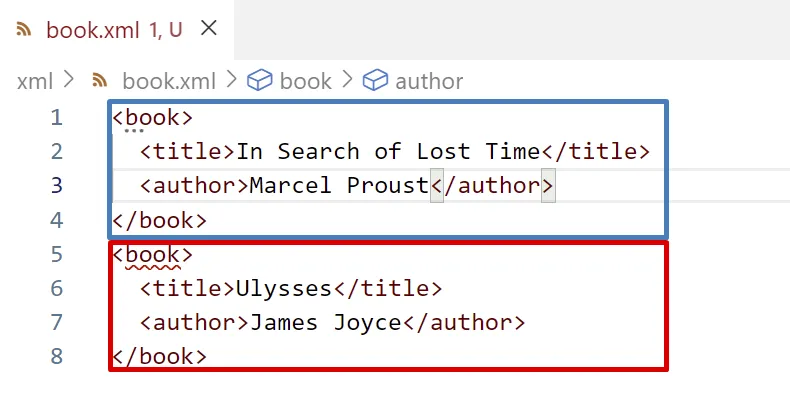
La solució és afegir un element pare dels dos elements <book> :
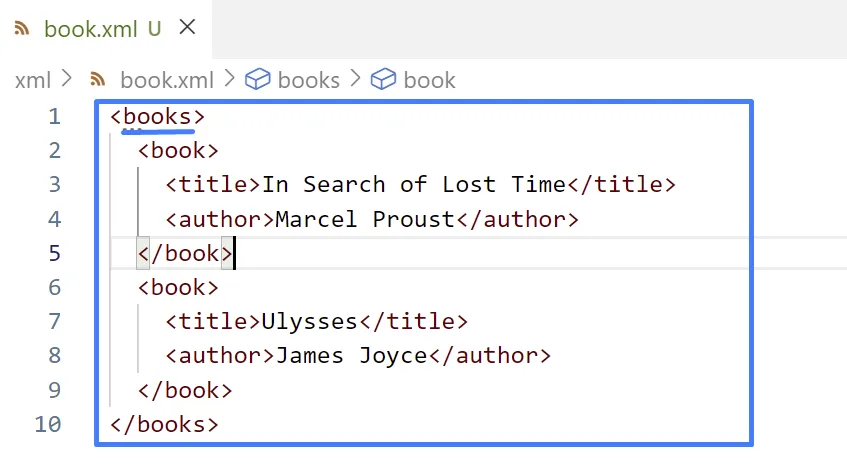
Per exemple el document XML que tens a continuació està ben format perquè inclou un i només un element arrel – encara que estigui buit:
<books></books>Nom de l’element
Tots els elements tenen un nom.
Aquest nom pot ser qualsevol nom, excepte que:
| Norma | Correcte | Incorrecte |
|-|-|
| Només pot començar amb una lletra. | order | $order |
| No pot començar amb xml | name | xml-name |
| No por tenir espais en blanc | last-item | last item |
Majúscules i minúscules
XML, igual que Linux, distingeix entre majúscules i minúscules.
Això vol dir que <first>, <FIRST> i <First> són elements diferents.
És una raó d’eficiència: el codi UTF-8 de F és 46 i el de f és 66.
A XML el significat de la paraula no l’importa gens ni mica, només que els bits de l’etiqueta d’inici siguin els mateixos que la etiqueta final.
Et pot semblar una tonteria, fins que tens un document XML molt extens, l’analitzador XML es queixa i no saps per qué.
Espai en blanc
El nom d’un element no pot tenir espais en blanc, però les dades si.
![]()
De fet, per XML una dada pot tenir tant espais en blanc com vulgis,
![]()
Final de línia
Per marcar el final de línia es fa servir una caràcter no visible que té el codi 10 LINE FEED (LF).
Però molts documents en Windows fan servir dos: un caràcter no visible que té el codi 13 CARRIAGE RETURN (CR) seguit del LF.
A XML no l’importa perquè els analitzadors elimen el caràcter CR, i Windows ha acceptat que el documents poden acabar la linea només amb LF.
Comentari
Els comentaris comencen amb l’string <!-- i acaben amb l’string -->:
<book> <!-- Book Title --> <title>In Search of Lost Time</title> <author>Marcel Proust</author></book>Element buit
Un element que no té contingut es pot escriure només amb una etiqueta.
Ja saps de {% link “/data/postgres/” %} que hi ha atributs que tenen el valor nul.
Això només és útil per escriure una mica menys, per a un analitzador és exactament el mateix:
<book> <title>In Search of Lost Time</title> <author/></book>Declaració
Normalment un document XML es guarda amb l’extensió .xml
Però el que determina que un document és un document XML és la declaració <?xml version=”1.0” ?> a l’inici del document – encara que és prescindible:
<?xml version="1.0" ?><book> <title>In Search of Lost Time</title> <author>Marcel Proust</author></book>Un document XML sempre comença amb els caràcters <?xml (< és el primer caràcter del fitxer).
La versió ha de ser 1.0 perquè amb la versió 1.1 pots tenir problemes d’interoperabilitat.
La codificació per defecte és UTF-8 que avui en dia és majoritària.
Dades d’intercanvi
XML és un format per intercanviar dades entre sistemes.
A continuació veurem un exemple d’un institut té una base de dades relacional per guardar la informació de la matrícula dels alumnes.
Base de dades
Aquest és el model de dades que farem servir:
classDiagram
class Alumne {
id
nom
}
Matricula --> Alumne
class Matricula {
id
curs
}
class Modul {
id
nom
}
class MatriculaModul {
nota
}
MatriculaModul --> Matricula
MatriculaModul --> Modul
Aquí tens una mostra del contingut de la base de dades (taules).
grau: id nom DAW Desenvolupament d’aplicacions web
mòdul: grau id nom DAW 2 Bases de dades DAW 3 Programació DAW 4 Llenguatges de marquesServidor
També té un servidor web amb una API que permet consultar dades de matrícula.
Per fer una petició s’ha d’enviar les dades de consulta en format XML.
Per exemple:
<consulta> <matricula> <alumne> <id>A3489</id> </alumne> <matricula></consulta>I una resposta podria ser aquesta:
<matricula> <id>M2023-345</id> <curs>2023</curs> <alumne> <id>A3489</id> <nom>Albert Vilaregut</nom> </alumne> <moduls> <modul> <id>0484</id> <nom>Bases de dades</nom> </modul> <modul> <id>0485</id> <nom>Programació</nom> </modul> <modul> <id>0373</id> <nom>LLenguatges de marques i sistemes de gestió de la informació</nom> </modul> </moduls></matricula>Pots veure que l’esquema és diferent al de la base de dades:
classDiagram
class Alumne {
id
nom
}
Matricula --> "1" Alumne
class Matricula {
id
curs
}
class Modul {
id
nom
}
Matricula *--> "1..*" Modul
Enlloc d’utilitzar una entitat de relació MatriculaModul, l’entitat Matricula agrega directament els mòduls en que està matriculat l’alumne.
Activitat
A continuació has de crear el model UML i un exemple de sol.licitut XML i resposta XML a:
1.- Consulta dels alumnes matriculats a un mòdul
{% sol %}
Consulta
<consulta> <modul>0373</modul></consulta>Resposta
<modul> <id>0373</id> <alumnes> <alumne> <id>A3489</id> <nom>Albert Vilaregut</nom> </alumne> <alumne> <id>Z2589</id> <nom>Gemma Alsina</nom> </alumne> </alumnes></consulta>{% endsol %}
2.- Consulta de tots els mòduls d’un grau amb número d’alumnes matriculats
Conclusió
-
El models de dades d’intercanvi són diferents dels de la base de dades.
-
Moltes vegades les dades d’intercanvi no provenen de la base de dades sinò del resultat dels procesos.
-
El model de la base de dades sempre ha d’estar ocult (és privat de l’aplicació).
-
El model de dades que exposa l’aplicació web és propi (no de la base de dades) i és públic.
-
El model de dades d’intercanvi forma part de l’API de l’aplicació web.
Repositori de dades
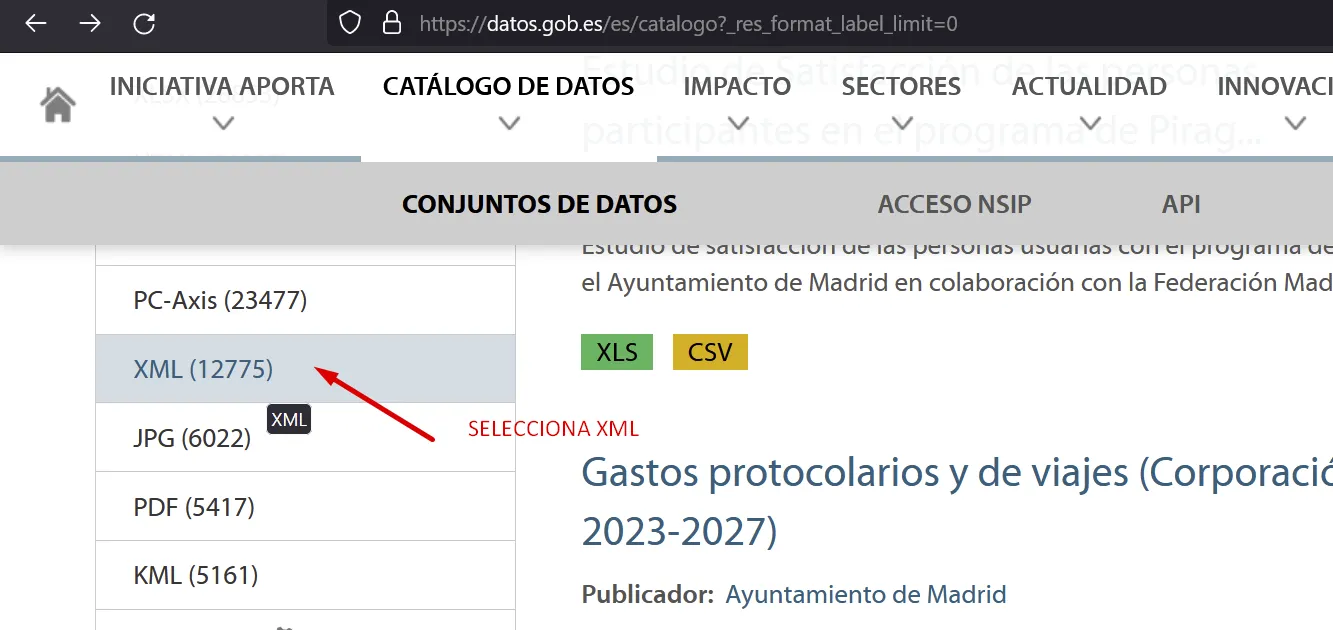
datos.gob.es
A Catálogo de datos pots trobar dades en diferents formats
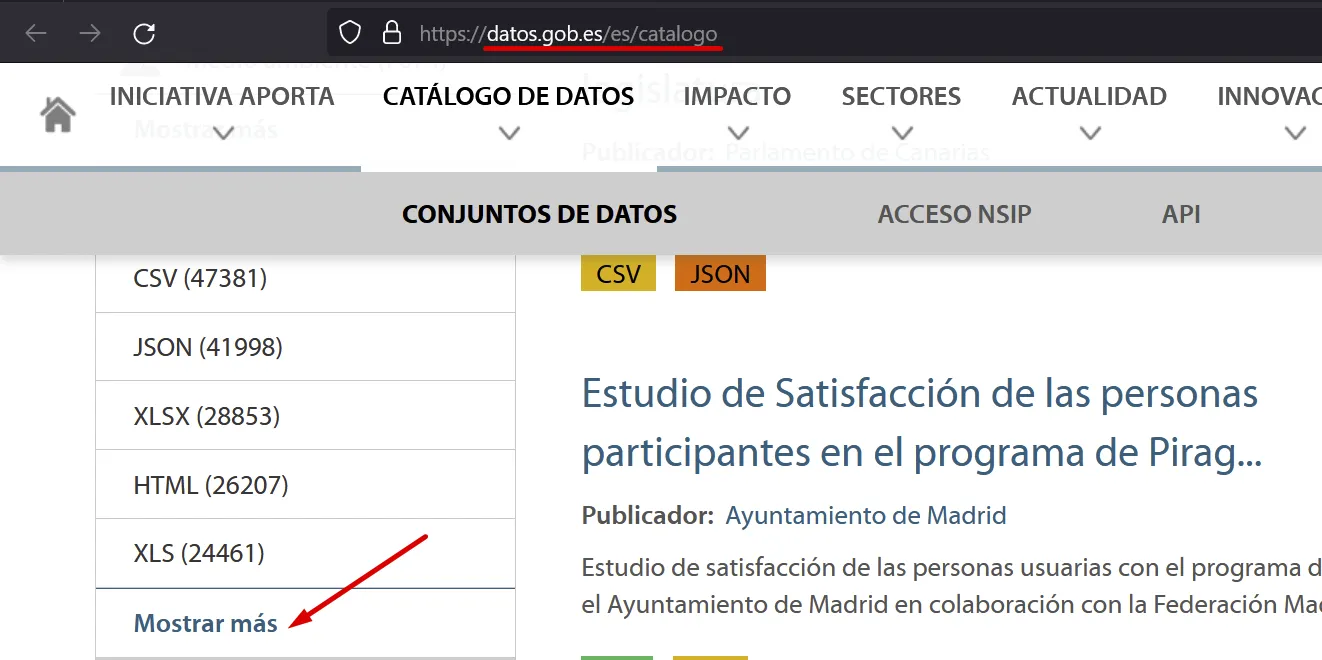
Fes clic en “Mostrar más” per poser seleccionar dades en XML:
Municipis
Un exemple són els Municipis de la Provincia de Barcelona en format XML: Municipis.
1.- Crea un document en blanc amb VSCode
2.- Copia el contingut del dataset al document de VSCode
3.- Dona format al document
Búsqueda
A la pàgina web de Catálogo de datos:
1.- Mira quins són els formats de dades que s’utilitzen habitualment.
2.- Mira alguns d’aquest fitxers i veurás que les dades són tabulars.
3.- Busca altra informació en XML
4.- Verifica que les dades no són tabulars encara que es faci servir XML.