Estadística
L'estadística ens permet extreure dades d'un conjunt enorme de dades de tal manera que ens permeten entendre les relacions entre les dades.
Introducció
…
Conceptes
Els estadístics són indicadors
Els valors estadístics només tenen sentit quan s’apliquen a un grup gran de dades, poques vegades en l’àmbit individual.
Per exemple, l’altura mitjana dels homes a Espanya és de 176 centímetres i el de les dones de 162 centímetres.
Quants en aquesta classe mesureu exactament aquesta altura?
Però la majoria us aproximeu a aquest valor.
Tipus de dades
Hi ha dades de diversos tipus.
Les dades quantitatives són dades numèriques que es poden mesurar, com pot ser el pes, l’edat o alçada.
Les dades qualitatives es tenen o no, per exemple el color dels ulls, la nacionalitat.
Mesures de tendència central
Els tres indicadors bàsics són la mitjana, la mediana i la moda.
Mitjana
La mitjana és un indicador que només es pot utilitzar amb dades quantitatives.
Consisteix a sumar totes les dades i dividir el resultat entre el nombre total d’elements.
Calcula la mitjana d’aquesta llista: [3, 8, 10, 13, 16, 18]
Show solution
=
= /
Python és un llenguatge pensant per enginyers i científics.
Per tant, a diferència d’altres llenguatges incorpora per defecte una llibreria d’estadística.
Pots calcular directament la mitjana de les dades anteriors amb statistics.
=
=
Moda
La moda és el valor que apareix més sovint.
En aquesta llista, quin és el valor que apareix més sovint?
= Show solution
És el 7
En aquest cas és més fàcil fer l’exercici a mà que escriure un codi en Python per a calcular la moda. 👻
Amb statistics podem calcular fàcilment la moda d’un conjunt de dades:
=
=
assert == , fPots observar que el resultat és una llista.
El motiu és que dos o més valors poden apareixen el mateix nombre de vegades.
=
=
assert == , fMediana
La mediana és el valor que està al mig d’un conjunt de dades ordenades.
=
=
assert == 7, fExemple
A continuació tens el salari mensual de 5 treballadors d’un pas no tan imaginari:
= Calcula la mitja, la moda i la mitjana:
Show solution
=
assert == 51685
assert == 4000
assert == 1000Dibuixa un gràfic de barres de les dades:
Show solution
Aquest pais podria ser els Estats Units, per exemple.
És un pais on el PIB per capita és dels més alts del món, on el seu mig és molt bo, on el ciutadà mig té un bon sou, però on una bona part de la població viu en la pobresa.
Pots veure que depen el conjunt de dades cada indicador explica una història diferent.
🤔
Exemple
Tenim les notes de 4 alumnes en 3 examens en un DataFrame. Seran números enters.
= : ,
: ,
: ,
:
})
=
)
= =,
=
)
Mesures de dispersió
Les mesures de dispersió descriuen com varien les dades respecte al seu centre.
TODO: Pendent de revisar completament a partir d’aquí
[Box Plot]((https://altair-viz.github.io/user_guide/marks/boxplot.html)
Rang
Rang: El rang és la diferència entre l’observació més alta (màxim) i la més baixa (mínim).
Rang = | Màx - Mín |
Desviació respecte a la mitjana: La desviació respecte a la mitjana és la diferència en valor absolut entre cada valor de la variable estadística i la mitjana aritmètica. La suma de les desviacions respecte de la mitjana és zero. Aquest càlcul es fa per a calcular el pendent de les rectes de regressió.
Quantil: Els quantils són punts presos a intervals regulars de la funció de distribució d’una variable aleatòria. Les mostres s’ordenen segons els valors de menor a major, i el quantil és el valor en aquest punt.
Si el punt es pren en tant per cent de les observacions, s’anomenen percentil. Si les observacions es divideixen en quatre quarts, les tres divisions es diuen quartils (Q1=25%, Q2=50%, Q3=75%). Q2 és la Mediana. També hi ha decils (D1=10%, … D9=90%) si volem filar més prim.
L’aplicació pràctica que haureu vist dels quantils és ordenar les publicacions científiques per H-Index, on les del Q1 són les més recomanades.
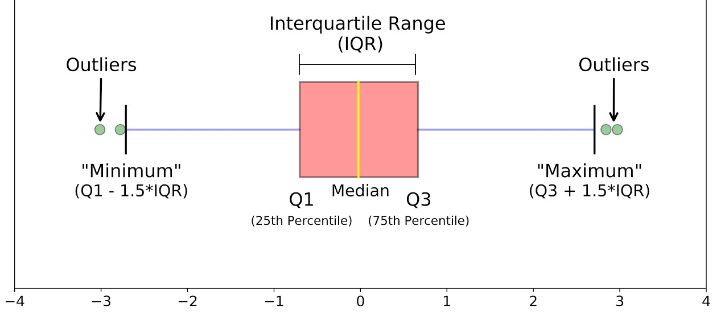
Rang interquartílic:
És la diferència (resta) entre el primer i el tercer quartil.
IQR = Q3 − Q1.
Com mostrar estadístiques descriptives ?
Molt senzill! Pandas proporciona una funció que ja hem vist des del primer dia: describe.
Les que aquesta funció no proporcioni (com la moda) són senzilles de calcular.
Provem-ho amb el dataset dels examens dels alumnes; amb 4 alumnes nous.
= : ,
: ,
: ,
:
}
= : ,
: ,
: ,
:
}
=
=
=
Resultat:
Fixeu-vos totes les estadístiques que hem aconseguit:
- count: Recompte de files/elements
- Mean: Mitjana aritmètica
- std: Desviació típica
- max i min: Màxim i mínim
- 50%: Mediana
- 25% i 75%: Quartil1 i Quartil3
Estadístiques generals, i també de tots els examens individualemnt (fa estadístiques de totes les dades numèriques).
Per calcular l’IQR, també ho tenim molt fàcil:
= -
El resultat és 7.75 - 5.75 = 2
1.- Estadístiques d’un institut.
Donat el dataframe de les notes dels 8 alumnes; realitza el següent.
- Mostra totes les estadístiques de les notes de l’examen 3.
- Mostra totes les notes de l’Anna i la Yaiza.
- Calcula l’IQR de les notes de la columna
Examen1. - Crea una columna anomenada
Finalamb lamitjana aritmètica dels 3 examens. - Mostra la mitjana aritmètica i desviació típica de tots els examens (columna
Final)
Assegura’t que el codi passi els tests que hem posat al final de tot.
= : ,
: ,
: ,
:
}
=
#El teu codi va aquí
# Tests
assert == 2,
assert . == 7,
assert == 7.25,
assert == 1.32, Valors indefinits: nan.
I què passaria si algú no fes l’examen en l’exemple anterior ? Com calcularia la mitjana ?
I si després el fes, com substituïriem la nota ?
Primer, ho representem amb el valor Nan, que es defineix així: np.nan.
# Afegir un nou alumne amb np.nan
= : ,
: ,
: ,
:
})
=
# Calcular la mitjana per a Marc (actualment amb np.nan)
=
# Reemplaçar np.nan per un 8
= 8
# Tornar a calcular la mitjana per a Marc
=
Com podem veure, per a realitzar operacions estadístiques pandas ignora els nan i només té en compte els valors existents.
Però per operacions matemàtiques si que és necessari ometre o reemplaçar per números els np.nan.
Valors atípics (outlier).
Un valor atípic (outlier) és una observació que difereix tan àmpliament de la resta de dades que podem pensar que s’ha comès un error.
Concretament, un valor outlier serà:
-
Un valor inferior al
quartil1 - 1,5 * IQR -
Un valor superior al
quartil3 + 1,5 * IQR
Recordm que l’IQR és el rang interquartílic: q3 - q1.
Sempre cal considerar-ne la causa. Si són causats per errors en la lectura de les dades o mesures inusuals s’esborren, però si no cal considerar-les.
Pandas és una molt bona llibreria, però encara no ha previst com calcular els outliers.
De tota manera, amb aquest senzill codi podrem trobar-los i eliminar-los.
Si només volem trobar-los, ens oblidem del loc.
=
=
= - #Interquartile range
= -1.5*
= +1.5*
=
return - Boxplot: Un boxplot és una gràfica que mostra diversos descriptors alhora d’una o més variables: Els
tres quartils,el "mínim" i "màxim" calculatsi elsoutliers. Són usats en molts àmbits.
Les llibreries com Seaborn o Matplotlib els generen molt fàcilment.
2.- Estadístiques de dispersió i outliers
Ens han donat un dataframe amb la edat, altura, pressió sistòlica i diastòlica de diversos pacients.
La pressió arterial normal, en el cas de la majoria dels adults, es defineix com una pressió sistòlica de menys de 120 i una pressió diastòlica de menys de 80.
Doncs bé, ens demanen mostrar estadístiques centrals i de dispersió de totes les variables, calcular l’amplitud interquartilica de les pressions i crear un nou dataframe sense els outliers de la pressió (sigui sis o dia).
Codi de partida:
= : ,
: ,
: ,
:
})
# Tractament dels outliersSolució esperada:
Show solution
'''
.
'''
=
=
= - #Interquartile range
= -1.5*
= +1.5*
# Si, es poden retornar 2 valors.
return ,
'''
.
'''
, =
=
return
= : ,
: ,
: ,
:
})
# la edat també té un iqr, però no l'esborrem perquè no passa res per
# tenir pacients grans.
# print('IQR edat',iqr(df_pacients,'edat'))
=
Creació de boxplot per estudiar els quartils de variables amb Seaborn.
Anem a crear gràfics de boxplot sobre l’exemple anterior dels pacients, concretament per a la pressió sistòlica.
Ho podem fer amb Matplotlib, però serà més senzill usar la llibreria de gràfics Seaborn. Cal importar-la amb la comanda:
En el codi que hem usat abans, hem d’afegir la creació de 2 boxplot, un amb els outliers i l’altre sense els outliers (que podem esborrar amb la funció remove_outliers)
'''
.
'''
=
=
= - #Interquartile range
= -1.5*
= +1.5*
# Si, es poden retornar 2 valors.
return ,
'''
.
'''
, =
=
return
= : ,
: ,
: ,
:
})
#print(df_pacients.describe())
# la edat també té un iqr, però no l'esborrem perquè no passa res per
# tenir pacients grans.
# print('IQR edat',iqr(df_pacients,'edat'))
=
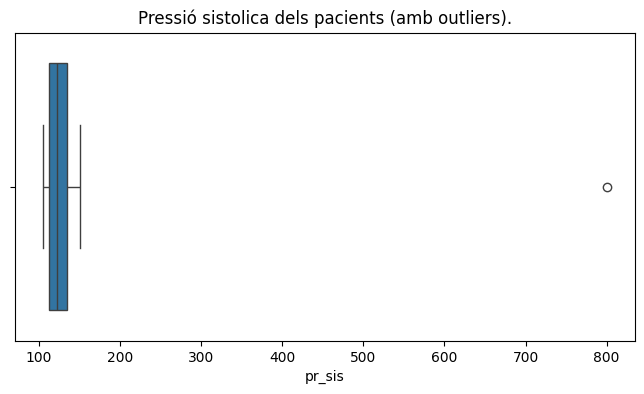
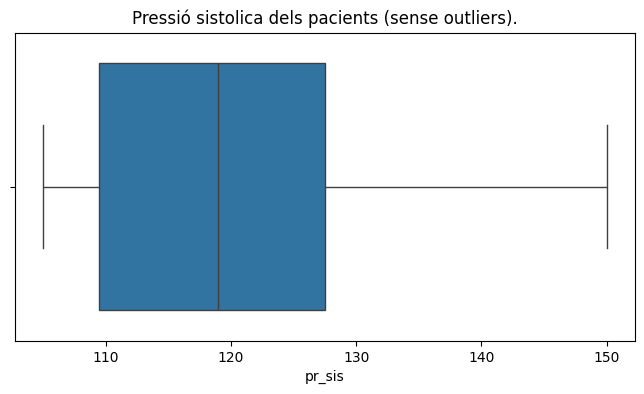
Fixeu-vos amb la sintaxis bàsica del gràfic boxplot de Seaborn:
- data Admet DataFrames, Series, dict, array, or list of arrays.
- x Variable que ens interessa (si a data hi ha DataFrame)
- y Si volem crear diversos plotbox classificats per un camp categòric com el gènere (si a data hi ha DataFrame)
- hue Si volem classificar encara més els boxplots.
Per tant, podem generar diversos plotbox d’una mateixa variable, classificats en camps categòrics (per exemple, un plotbox per homes i un altre per dones).
Ho podreu veure amb un exemple sobre un dels datasets més coneguts del món, el dels passatgers del Titanic, que té un munt de carecterístiques de cadascun
No ens caldrà descarregar-lo perquè Seaborn ja incorpora uns quants dataSets descarregats que podem importar fàcilment a un dataFrame.
=
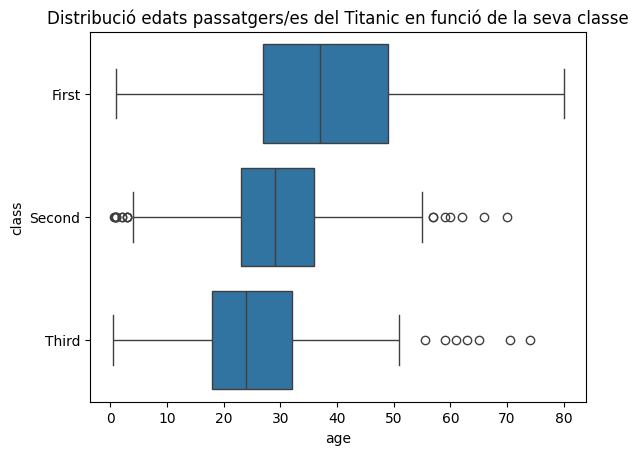
Fixeu-vos! Amb només dues linies noves ho hem aconseguit :)
Recompte de variables agrupat per categories amb Seaborn.
Partint del mateix exemple dels passatgers del Titanic i Seaborn; imaginem-nos que volem saber el número de passatgers homes i dones de cada classe.
Com ho fem ? Amb el gràfic de Seaborn catplot, que genera diagrames de barres classificables per diversos criteris (la x i el hue) i que permet fer operacions automàtiques dins del grup amb el paràmetre kind.
# Now let separate the gender by classes passing 'Sex' to the 'hue' parameter
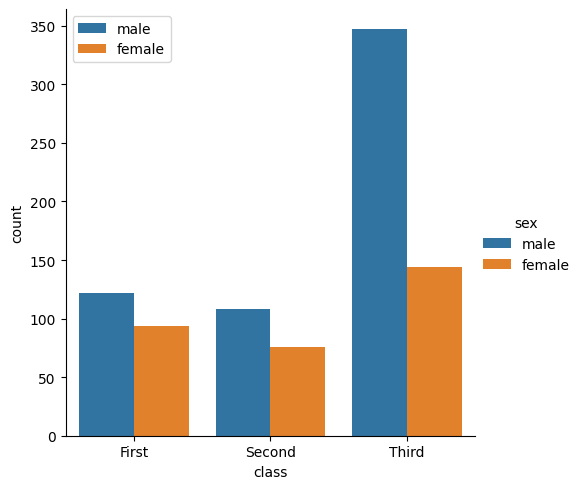
Teniu més d’exemples d’ús de catplot a la web de Seaborn
3.- Crea un gràfic que que mostri quants superivents hi ha hagut de cada classe de bitllet (First,Second,Third)
Show solution
Distribució normal
La naturalesa no és una fábrica amb un procés industrial que fabrica components d’alta qualitat tots exactament iguals.
Més aviat són elements fets a mà en què la majoria s’assemblen, però en cap cas tots són iguals.
Una de les distribucions teòriques més utilitzada a la pràctica és la distribució normal, també anomenada distribució gaussiana en honor al matemàtic Carl Friedrich Gauss.
Charles Darwin i el seu cosí Francis Galton van descobrir que les variables associades a fenòmens naturals i quotidians que experimenten totes les espècies (inclòs l’ésser humà) segueixen, aproximadament una distribució normal.
Distribució normal vol dir que la majoria dels subjectes segueixen més o menys el que és la norma respecte a aquella dada.
Per exemple, si la norma és que l’alçada dels espanyols és de 176 centímetres una gran majoria més o menys ho són.
Forma i propietats distribució normal.
- La mitjana, la moda i la mediana són iguals.
- L’àrea total sota la corba és igual a 1.
- La corba és simètrica al voltant de la mitjana.
- És ideal per a representar variables numèriques contínues (com la alçada, la edat de persones…)
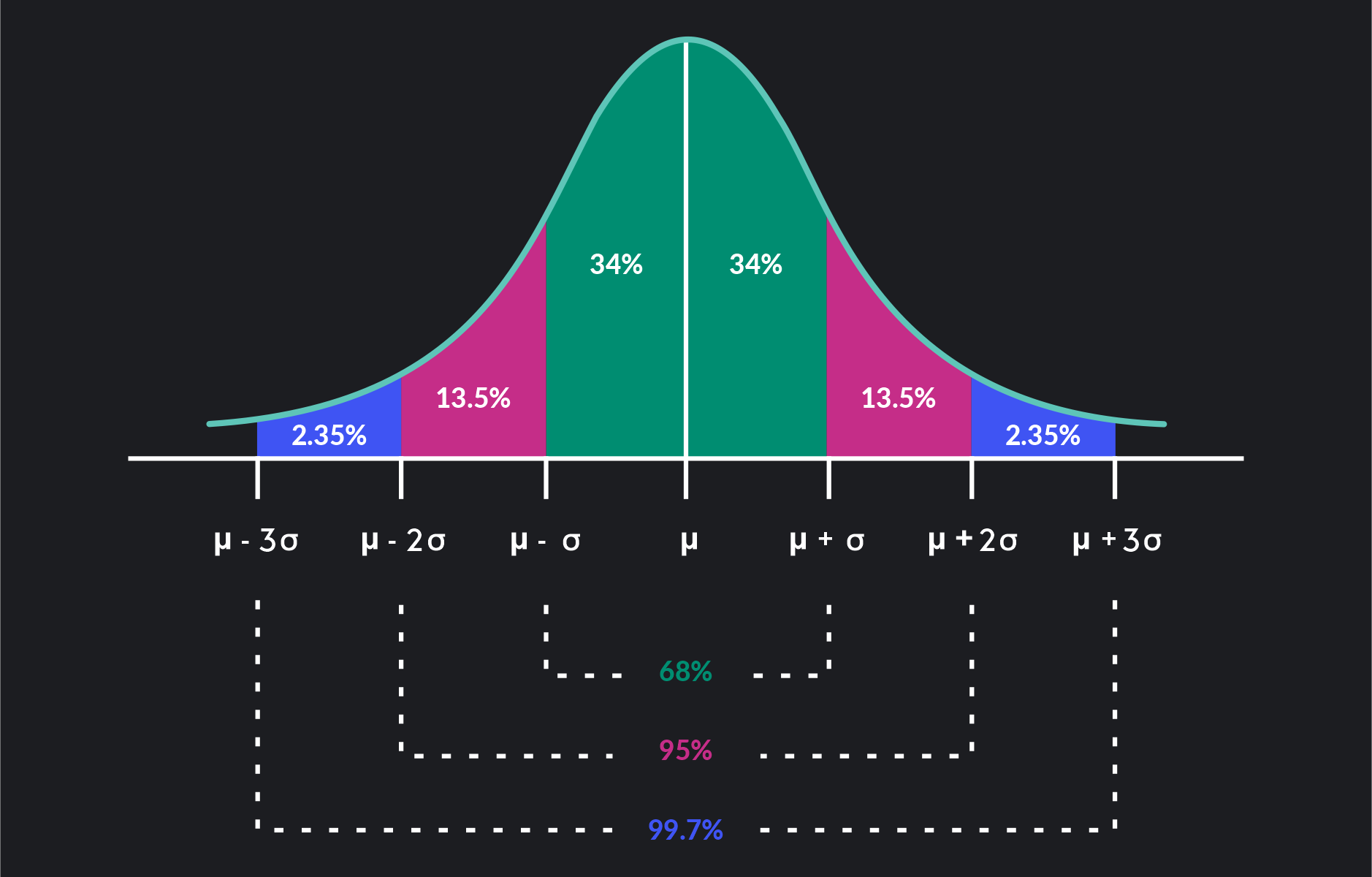
D’aquesta corba podem deduïr els següents intèrvals de confiança (IC):
- El 68% aprox. de les dades es troben dins d’una desviació estàndard de la mitjana.
- El 95% aprox. de les dades es troben dins de dues desviacions estàndard de la mitjana.
- El 99,7% aprox. de les dades es troben dins de tres desviacions estàndard de la mitjana.
I per a què ens serveixen aquestes propietats ?
Si volem estudiar probabilitats, ens va bé per deduïr que hi ha un 2,38% de probabilitats (aprox) que un esportista tingui una alçada superior a la mitjana + desviació típica multiplicada per 2.
Ho pots entendre millor veient la corba de distribució:
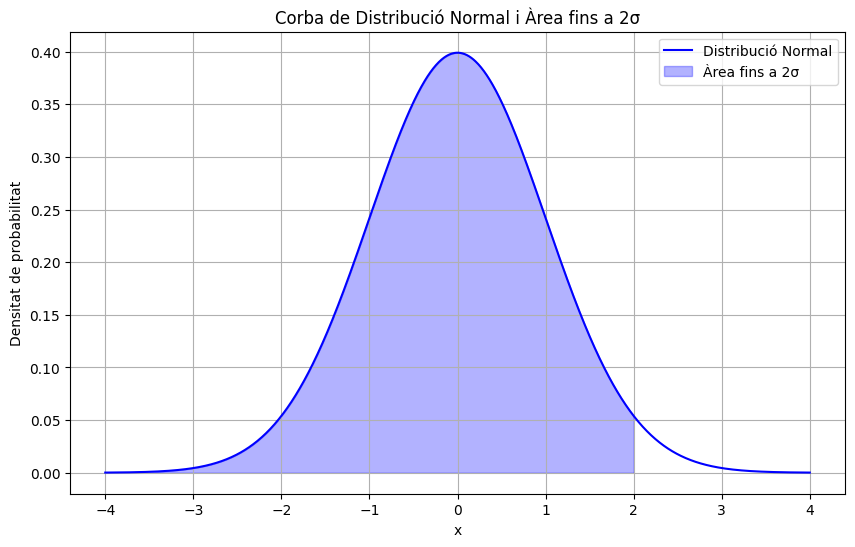
Si tens curiositat com hem creat la corba, aquí tens el codi:
Show solution
# Càlcul del percentatge dins de +2 sigma
= 0
= 1
= * 100
# Dibuixar una corba de distribució normal estàndard
= # Valors de x des de -4 fins a 4
= # Funció de densitat de probabilitat per a una normal estàndard
# Àrea sota la corba des de l'inici fins a 2 sigma
=
=
La segona distribució més comuna és la distribució binomial; que sol donar-se en obtenir mostres del clima (temperatures, pluges…) i també en esdeveniments on intervé l’atzar (l’aletorietat): probabilitat d’obtenir una cara d’un dau, una moneda…
Aprofundir en els tipus de distribucions en estadística queda fora de l’abast d’aquest tutorial.
De fet, ja ho vam veure a la sessió de Matplotlib
Exemple distribució normal.
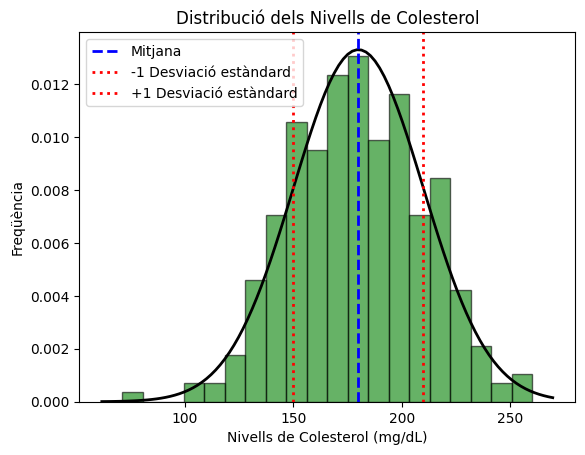
Anem a veure com dibuixar un histograma i una corba d’una distribució Normal. que servirà per a comparar si la nostra mostra té una forma semblant a la corba normal.
Per aquest exemple usarem una funció molt útil de Numpy que genera dades que segueixin una distribució normal.
Veiem-ho amb un exemple fictici del nivell de colesterol a la sang de 300 pacients.
# Paràmetres per a la distribució normal
= 200 # mitjana del colesterol (mg/dL)
= 30 # desviació estàndard (mg/dL)
= 300 # nombre de mostres
# Generar dades aleatòries amb una distribució normal
=
# Crear l'histograma
# Crear la corba de distribució normal
, =
=
= /
# Afegir títol i etiquetes
# Afegir línia vertical a la mitjana
# Afegir línies verticals als intervals de confiança (±1 desviació estàndard)
La sintaxis de la funció np.random.normal és:
- loc Mitjana aritmètica (mean) de la distribució.
- scale Desviació típica (std_dev) de la distribució. Ha de ser no negatiu.
- size Tamany (número d’elements) de la mostra
En quant a la sintaxi de plt.hist() remarquem el següent:
- data El més important, on li passem les dades.
- bins Matplotlib divideix els valors de la variable contínua en 20 intèrvals discrets, en 20 barres (bins=20).
- density Les àrees de les barres es normalitzen perquè la suma total sigui 1 (density=True).
- color Lletra per representar el color ‘g’ -> green.
- alpha Transparència del color del 60%.
- edgecolor Color de les vores.
Us animem a provar aquest diagrama, i a cercar altres exemples. És molt satisfactori realitzar aquest diagrama tan complet amb només 3 llibreries de Python i la comprensió de conceptes estadístics bàsics :)
Variància: La variància és la mitjana aritmètica del quadrat de les desviacions respecte a la mitjana d’una distribució estadística. La variància intenta descriure la dispersió de les dades. En resum, la variància seria la mitjana de les desviacions al quadrat. Es representa com σ2 (sigma minúscula al quadrat).
Desviació típica: La desviació típica és l’arrel quadrada de la variància. Es representa amb la lletra grega σ. En anglès es conèix com std = Standard Desviation.
Mesures de correlació
En moltes ocasions, ens pot interessar analitzar si ha una relació directa o inversa entre 2 variables d’una mostra.
Per exemple entre el temps i les temperatures, entre el pes i l’alçada de persones, l’edat i el nivell de sucre o el pes i el nivell de sucre.
Fins i tot, podem mostrar un mapa de correlacions, entre una variable i les altres variables (sempre i quan siguin quantitatives i del mateix tipus).
Anem a veure-ho amb un exemple senzill, el dataset tips; que conté dades de propines proporcionades per clients d’un bar, on tenim les dades de: preu del menjar(bill), gènere(sex), diners propina (tips), si és dinar o sopar(time), el número de persones(size), etc…
# Carregar el dataset de propines
=
# Seleccionar només les variables numèriques
=
# Calcular la matriu de correlació
=
# Crear el heatmap de correlació
# Crear el scatter plot
Fixeu-vos amb el mapa; com correlaciona totes les variables mumèriques: total_bill, tips, size:
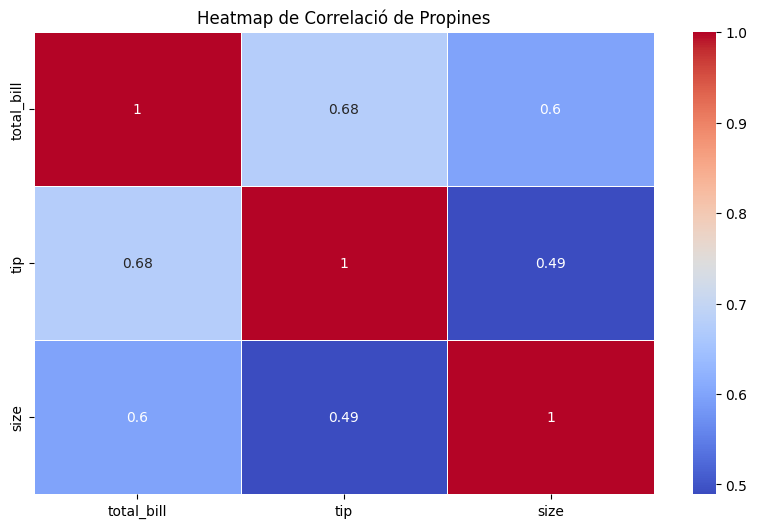
Podem observar una correlació directa:
- 0,68 entre el preu del menjar (total_bill) i els diners de propina (tips)
Diem que 2 variables estan fortament correlacionades directament si aquesta correlació és de 0,7 o superior, on el màxim és 1.
Per tant, en el nostre cas obtenim la informació que sovint (no sempre) es compleix com més val el que s’ha menjat més s’agraeix al servei en diners de propina superiors.
Finalment, comentar que hem dibuixat un altre gràfic de punts (scatterplot) que mira si hi ha correlació entre les propines i el preu del menjar, agrupat entre el temps de dinar i de sopar; perquè sempre va bé observar aquests gràfics per fer-nos una idea de la correlació de 2 variables a simple vista.
Seaborn també proporciona un altre tipus de gràfic molt potent per analitzar la distribució i correlació entre les variables, i fins i tot agrupar-les per una variabla categòrica (com poden ser ‘Time’, ‘Sex’ o ‘Smoker’).
=
# Crear el pairplot amb línies de millor ajustament
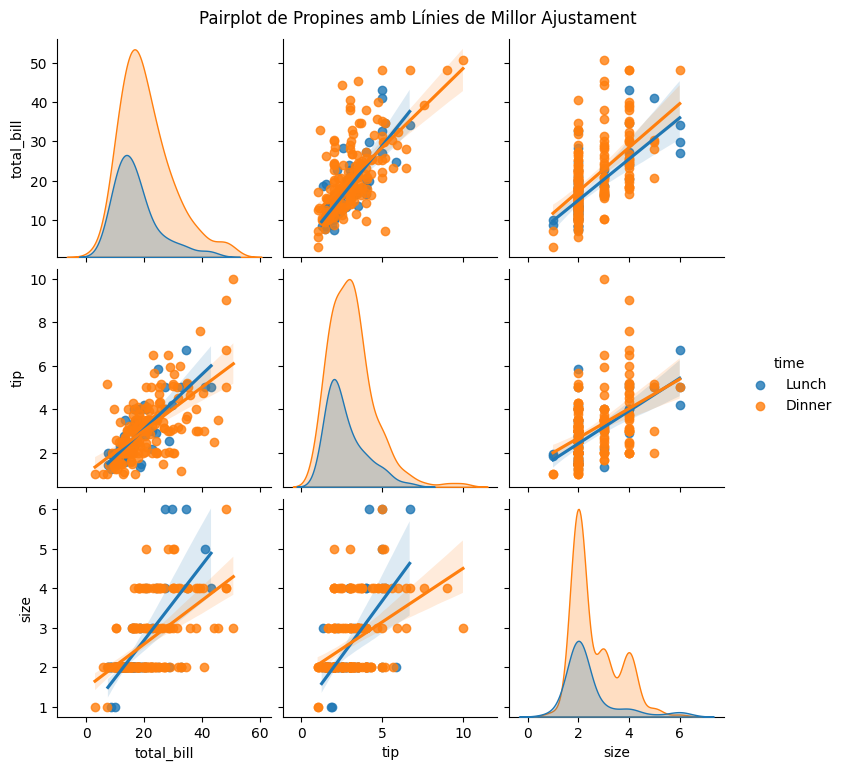
4.- Agafa el dataset dels pingüins de Palmer (també inclòs a Seaborn) i dibuixa la matriu de correlació entre totes les 4 variables numèriques. Comenta si has vist una forta correlació entre algún parell de variables.
Completa el codi per aconseguir-ho:
= Show solution
=
=
Hi ha una forta correlació entre la longitud de les aletes i el pes dels pingüins (de 0,87 sobre 1).