Basic
Streamlit és un framework per crear aplicacions web per analitzar dades.
Introducció
Streamlit és un framework per crear aplicacions web per analitzar dades.
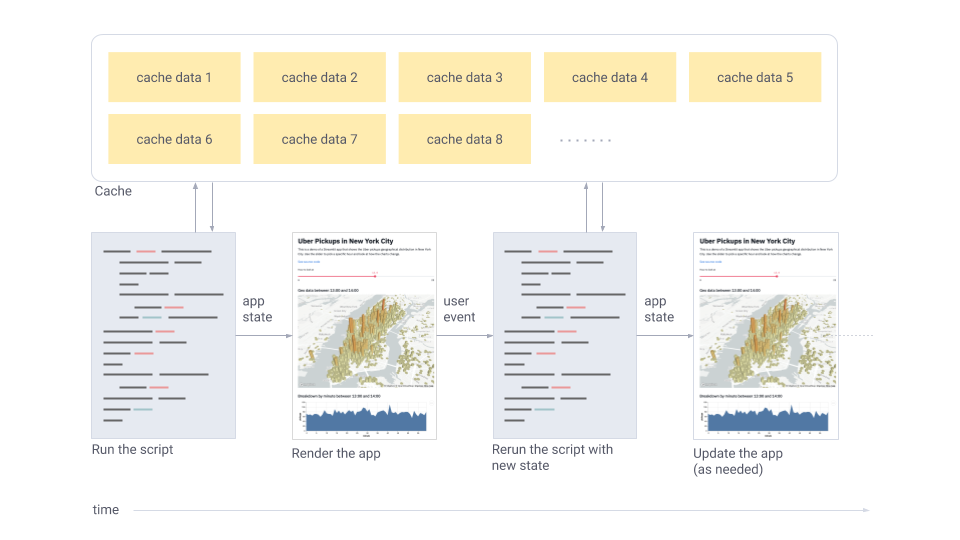
- Les aplicacions de Streamlit són scripts de Python que s’executen de dalt a baix.
- Cada vegada que un usuari obre una pestanya del navegador apuntant a la teva aplicació, l’script s’executa i s’inicia una sessió nova.
- A mesura que l’script s’executa, Streamlit dibuixa la seva sortida en directe en un navegador.
- Cada vegada que un usuari interactua amb un widget, el teu script es torna a executar i Streamlit redibuixa la seva sortida al navegador. El valor de sortida d’aquest widget coincideix amb el valor nou durant aquesta reexecució.
- Els scripts utilitzen la memòria cau de Streamlit per evitar recalcular funcions costoses, de manera que les actualitzacions es produeixen molt ràpidament.
- Session State et permet desar informació que persisteix entre reexecucions quan necessites més que un simple widget.
- Les aplicacions de Streamlit poden contenir múltiples pàgines, que es defineixen en fitxers
.pyseparats.
Script
Crea un projecte streamlit-basic amb Uv:
uv init streamlit-basic
cd streamlit-basic
uv add streamlitModifica el fitxer main.py:
Després l’executes amb streamlit run:
uv run streamlit run main.pyTan bon punt executes l’script com es mostra a dalt, s’aixecarà un servidor local de Streamlit i la teva app s’obrirà en una pestanya nova del navegador per defecte. L’app és el teu llenç, on dibuixaràs gràfics, text, ginys, taules i més.
El que es mostra a l’app depèn de tu. Per exemple, st.text escriu text en brut a la teva app.
Flux de desenvolupament
Cada vegada que vulguis actualitzar la teva app, desa el fitxer font. Quan ho facis, Streamlit detecta si hi ha canvis i et pregunta si vols tornar a executar l’app. Tria “Always rerun” a la part superior dreta per actualitzar automàticament la teva app cada vegada que canviïs el codi font.

Això et permet treballar en un bucle interactiu ràpid: escrius una mica de codi, el deses, ho proves en viu, tornes a escriure codi, el deses, ho proves, i així successivament fins que estiguis satisfet amb els resultats. Aquest bucle ajustat entre codificar i veure resultats en viu és una de les maneres en què Streamlit et fa la vida més fàcil.
Mentre desenvolupes una app amb Streamlit, es recomana col·locar l’editor i el navegador costat per costat, per poder veure el codi i l’app alhora. Prova-ho!
Estàs llegint una vista prèvia.
Inicia sessió per llegir la pàgina completa. L'alumnat i el professorat hi accedeixen amb el compte del Moodle del centre.
Inicia sessió